|
百度如何判断伪原创和原创?百度喜欢什么样的文章?什么样的文章比较例如获得长尾词排名?等等诸如此类的问 题。面对这些问题,我常常不知如何回答。如果我给一个比较大方向一些的答案,例如要重视用户体验、要有意义等等,那么提问者会觉得我在应付他,他们往往抱 怨说这些太模糊。可是我也没法再给出具体的内容,毕竟我不是百度,具体算法我又何德何能的为你们指点江山呢?下面中的我皆至来去留网站的观点,均以参考为目的,不以理论作教材,由此照成后果均有自己承担。
为此,我开始写这个“如果 是我”系列的文章,“如果是我”代表来去留网站自己的想法。在这一系列文章里,我假设如果是我绞尽脑汁的来为网民提供较好的搜索服务,我会怎么做,我会怎么对待文章内容、如何对待外链、如何对待 网站结构等等诸如此类的站点元素。当然,本人技术有限,我只能写一点我稍微理解的东西。而百度以及其它的商业搜索引擎,他们有大量比我优秀的人才,相信他 们的算法以及处理问题的方式会比我完善很多,而我之所以写这些,无外乎抛砖引玉,希望大家看后,心里有一个大概。毕竟在SEO的道路上走过一段时间后,没 有谁能够当谁的老师,一些观点仅供参考。 ************重要的声明******************************* 在此,我要郑重声明,这个系列文章中所有涉及到的思想、算法与程序,均非本人所写,全部是我从一些公开的资料里搜集而得的。同时,相信大家也能理解,如果这些免费公开的东西都能做到如此程度,那么那些商业机密就更不用提了。 ****************************************************** 好的,现在开始。 如果是我,我会喜欢什么样子的文章呢?我会喜欢我的用户喜欢的文章,如果硬要加判定标准,那无外乎是两种:1.原创且用户喜欢。2.非原创且用户喜欢。 在这里,我的态度很明显,伪原创就是非原创。那么用户喜欢什么样的文章呢?很显然,一些新观点、新知识往往是用户喜欢的,也就是说通常原创文章都是用户喜 欢的,而且即便用户不喜欢,原创站点作为新鲜内容的制造者,也应该受到一定的保护。那么非原创的文章用户就一定不喜欢吗?诚然否也。一些站点,其内容往往 是经过搜集整理后聚合而成的,那么这些站点对用户来说就是有价值的,其相对应的文章理应获得较好的排名。 由此可见,我需要重视两类文章即可。一是原创文章,二是有价值的信息聚合站点下的文章。 首先要明确一点,本文探讨范围仅限内容页,而非专题页、列表页和首页。 那么我在甄别这两类文章之前,我需要先进行信息的采集。本文对于spider程序部分不进行阐述。当spider程序下载下来网页信息后,在内容处理的模块中,我需要先对内容除噪。 内容除噪,并非大家经常性的误以为仅仅除去代码而已。对于我来说,我还要出去页面部分非正文内容的文字。比如导航条、比如底部文字以及各个文章列表。将 它们的影响除去后,我将得到一段仅仅包含网页正文内容的文本段落。写过采集规则站长朋友应该知道,这个并不难。但搜索引擎毕竟是一款程序,不可能针对每个 站写个类似于的采集规则的东西,所以我需要建立一套除噪算法。 在此之前,我们先明确我们的目的。
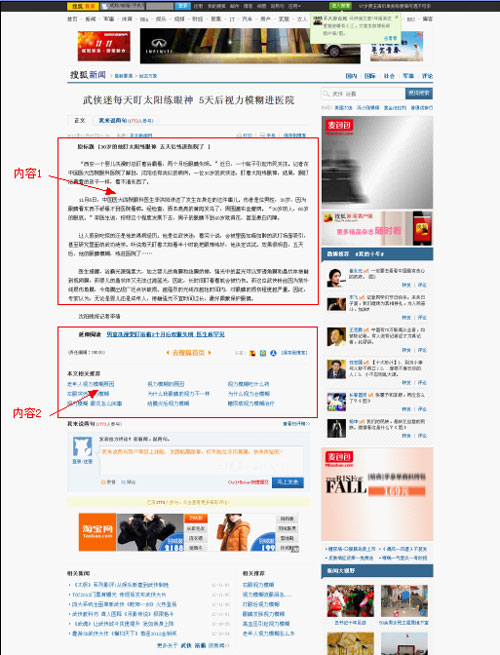
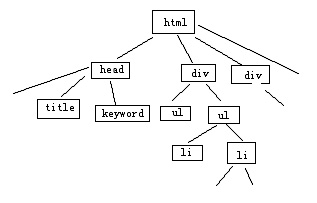
上图中很明显内容1是用户最为需要的,内容2是用户可能感兴趣的,其余均是无效的噪音。那么针对于此,我们可以发现如下几特征: 1.所有的调用列表全部是在一个信息块里,这个信息块绝大部分是由<a>标签组成,即便有游离于<a>标签的内容,其文字也基本是固定的,且在站内页面中存在大量重复,较为容易判断。 2.内容2一般紧邻着内容1。而且内容2中的链接锚文本,与内容1存在相关性。 3.内容1部分,是有文字文本内容和<a>标签混合而成,且在通常情况下,文本文字内容在网站网页集合中具有唯一性。 那么,针对于此,我采用广为人知的标签树方式,将内容页进行分解。 从网页的标签布局上来看,网页是通过若干的信息块来提供内容的,而这些信息块又是由特定的标签规划出来的,常见的标签 有<div><ul><li><p><table><tr><td> 等,我们依照这些标签,将网页费解为树状结构。
上图是我手绘的简单的标签树,通过这种方式,我可以非常轻松的识别出各个信息块。然后我设定一定阙值A为内容比重阙值。内容比重阙值为信息块中文本字数 与<a>标签出现此处的比值。我设定当网页中信息块内容比重阙值大于A时,才会被我列为有效内容块(此举是为了杜绝过分的多内链,因为如果一 篇文章布满内链,则不利于用户体验),然后我再比对内容块中的文本,当其具有唯一性时,此一个或多个内容块的集合,即为我所需要的“内容1”。 那么内容2我要如何处理呢?在讲解处理内容2之前,我先讲解一下内容2的意义。正如我先前所说,如果是一个注重用户体验的聚合性网站,那么他的作用是将 现有的互联网内容经过精心的分类与关联,来方便用户更好、更有效的阅读。针对这样的站点,即便其文章不是原创而是从互联网上摘抄的,我也会给予其足够的重 视与排名,因为它良好的聚合内容往往更能满足用户的需求。 那么针对聚合站点,我可以通过“内容2”来进行粗略的判断。简而言之,如果是一个良好的聚合站点,首先其内容页必须存在内容2,同时内容2必须占重要部分。 好了,识别内容2很简单,对于内容比重阙值低于某个特定值的信息块,我全部判断为链接模块。我将内容1通过某些方式(具体方式本文后半部分讲解),提取 出主题B。我将链接模块中的所有<a>标签的锚文本分别进行分词,如果所有的锚文本均与主题B相符,则将此链接模块判定为内容2。设定链接阙 值C,链接阙值为内容2中<a>标签出现次数除以所有链接模块所出现的<a>标签次数所得的比重,若大于C,则此网站可能为聚合 网站,针对内容排名计算时会引用聚合站点特定的算法。 (责任编辑:laiquliu) |